


Building a Neural Network to Prevent Fraud in Banking
Unraveling the complexities of artificial neural networks (ANNs) can be as thrilling as it is daunting, but not when you're armed with the right guide. Dive into our latest post where we demystify the process of constructing an ANN, designed to predict customer behavior with high accuracy. We'll take you from the ground up, from initializing the network layers to watching your model's predictions unfold and evaluating the results.

Artificial Neural Networks (ANNs) have become essential tools in data science, offering versatility and strength in processing and learning from large datasets. They are transforming various industries by providing insights that were previously unattainable.
Top Applications of ANNs
- Financial Fraud Detection:
ANNs enhance the ability of financial institutions to detect fraudulent transactions with remarkable precision. - Personalized User Experiences:
In the tech sector, ANNs enable platforms to adapt to individual user preferences, creating tailored interactions. - Supply Chain Optimization:
Manufacturers use ANNs to predict and streamline logistics, improving efficiency in the supply chain.
ANNs in Consumer Credit Risk
For banks and lenders, accurately assessing credit risk is critical. Traditional methods often fall short, leading to uncertainty. ANNs offer a superior solution by providing deep insights into a borrower's financial behavior.
Taking Credit Risk Assessment to a new level with ANNs
- Credit History Analysis: ANNs evaluate a person's financial history to estimate the likelihood of debt repayment.
- Transaction Pattern Examination: They analyze spending habits to identify indicators of financial stability or potential issues.
- Customized Credit Limits: By understanding an individual's financial health, ANNs help institutions set appropriate credit limits, reducing the risk of over-lending.
The Self-Improving Nature of ANNs
ANNs continually learn from new data, refining their predictions over time. This ongoing improvement enhances their effectiveness and reliability.
AI in Finance
In the financial sector, ANNs are more than just tools—they are catalysts for change. Their ability to provide accurate predictions in credit risk assessment helps secure a more stable financial future for both lenders and borrowers.
Exploring the Implementation
Purpose and Data Import
We aim to use an ANN to predict whether bank customers will default on their credit card payments next month. To calculate the probability of default, we'll implement the sigmoid activation function in the output layer of our network.
Dataset Overview
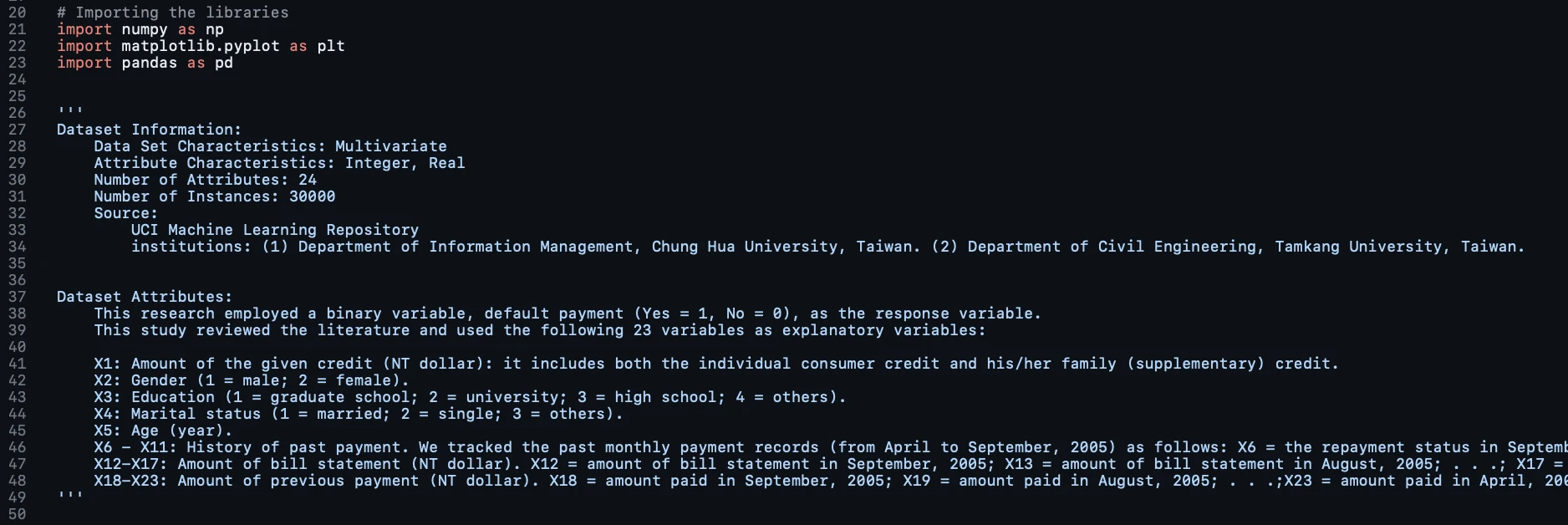
Our dataset includes 30,000 records with 24 attributes such as credit amount, demographics, payment history, and previous payments. This multivariate dataset is sourced from the UCI Machine Learning Repository.
Setting Up the Environment
We begin by importing essential libraries:
- NumPy for numerical computations
- Matplotlib for data visualization
- Pandas for data manipulation
Next, we load the dataset into a Pandas DataFrame. Since the dataset has a two-header format, we adjust the import settings to skip the extra row for accurate data alignment.
Data Preprocessing
- Creating Feature Matrix (X): The independent variables (attributes that predict the outcome) are extracted into a matrix called X. It selects all rows and columns 1 through 23, excluding the ID column.
- Creating Output Vector (y): The dependent variable (the outcome to be predicted) is stored in a vector y. It's the last column of the dataset, indicating whether the customer defaulted.
Data Preparation for ANN
- Data Encoding: Encoding categorical data is unnecessary for this dataset, as all variables are numerical.
- Splitting the Data: The dataset is split into training and testing sets using train_test_split from sklearn.model_selection, with 80% of the data for training and 20% for testing.
- Feature Scaling: The StandardScaler from sklearn.preprocessing is used to normalize the feature data, ensuring that all input features contribute equally to the analysis and speeding up the calculations.
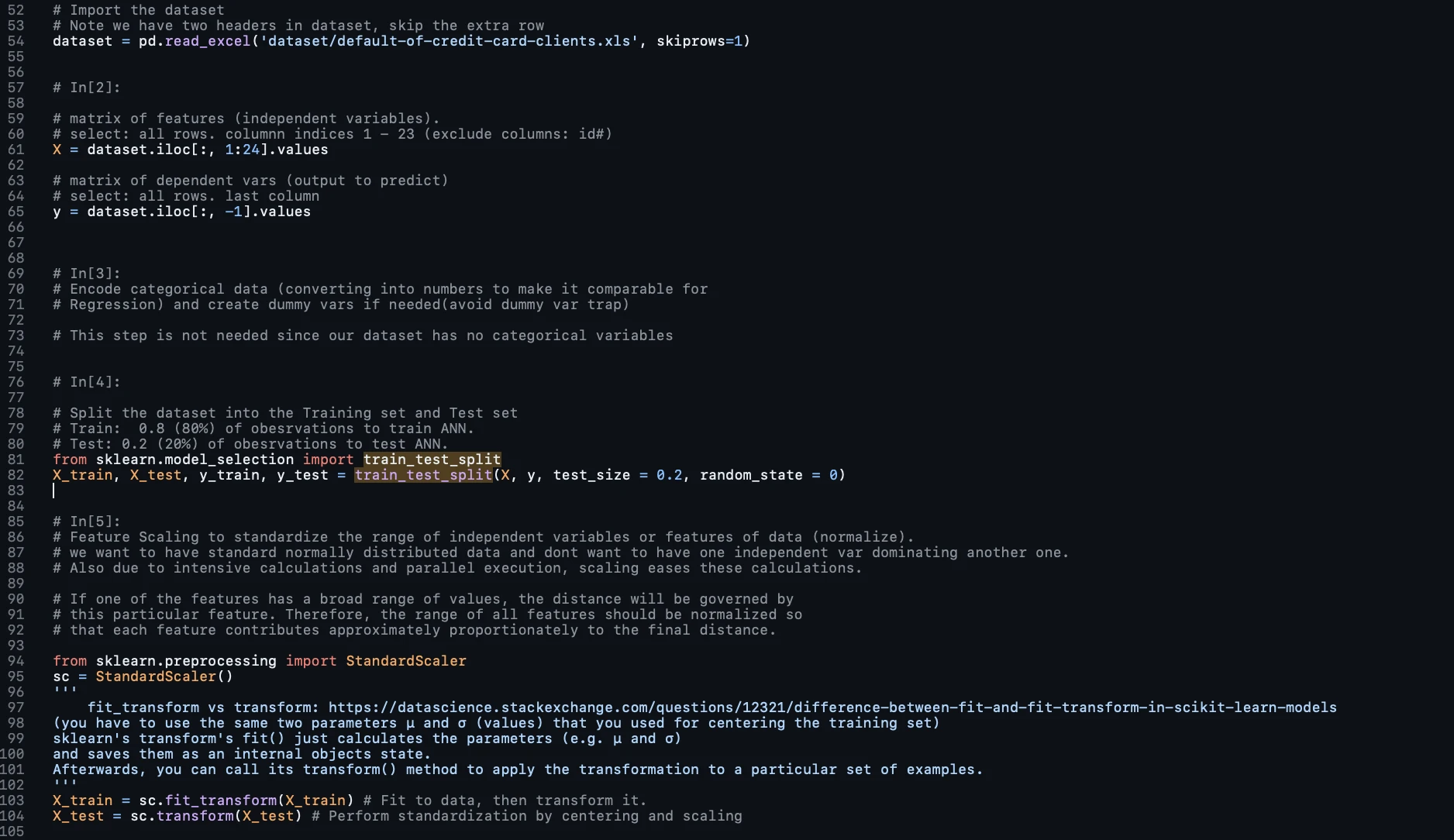
Defining the Output Layer and Compiling the ANN
We define the output layer of the artificial neural network and compile the entire network. The output layer is responsible for providing the final prediction, which in this case is whether a customer will default on their payment next month. Since it's a binary classification problem (default or no default), a single neuron is sufficient in the output layer.
The activation function used is the sigmoid function because it produces a probability outcome that ranges between 0 and 1. This is crucial for ranking customers based on their probability of default.
The compilation of the neural network involves specifying the optimizer, which is the algorithm that adjusts the weights to minimize the cost function. Here, 'adam' is a popular stochastic gradient descent-based optimizer. The loss function 'binary_crossentropy' is appropriate for binary classification problems. Lastly, metrics like 'accuracy' are used to evaluate the model during training and testing.
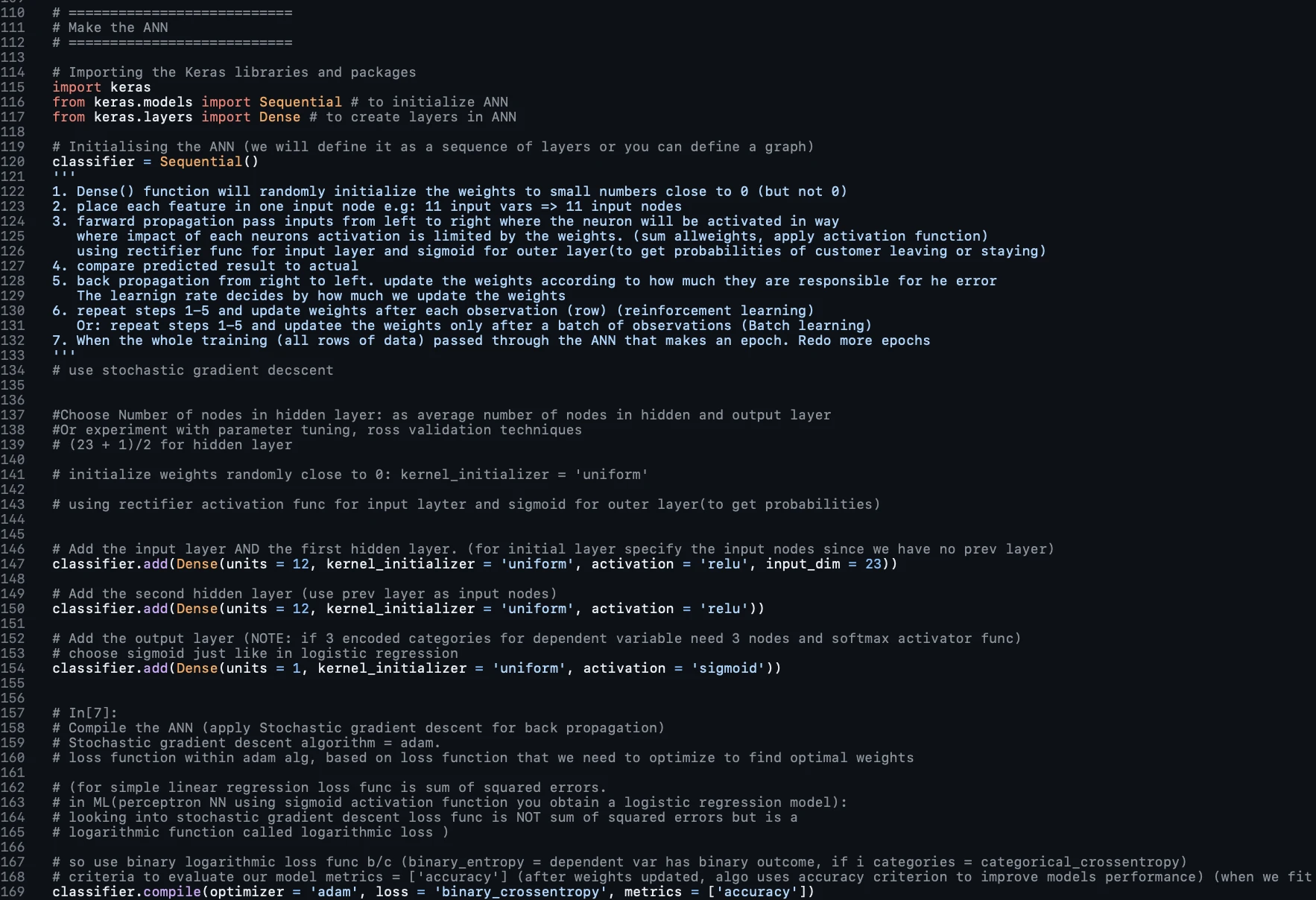
Fitting the ANN to the Training Set
Once the ANN is compiled, it needs to be trained with the data. This is done using the fit method, which takes the training data as input and trains the model for a specified number of epochs. An epoch is an iteration over the entire dataset. Additionally, a batch size is defined to specify the number of samples after which the model weights will be updated.
The choice of batch size and number of epochs can significantly affect the performance and speed of the learning process and would typically be determined through experimental tuning.
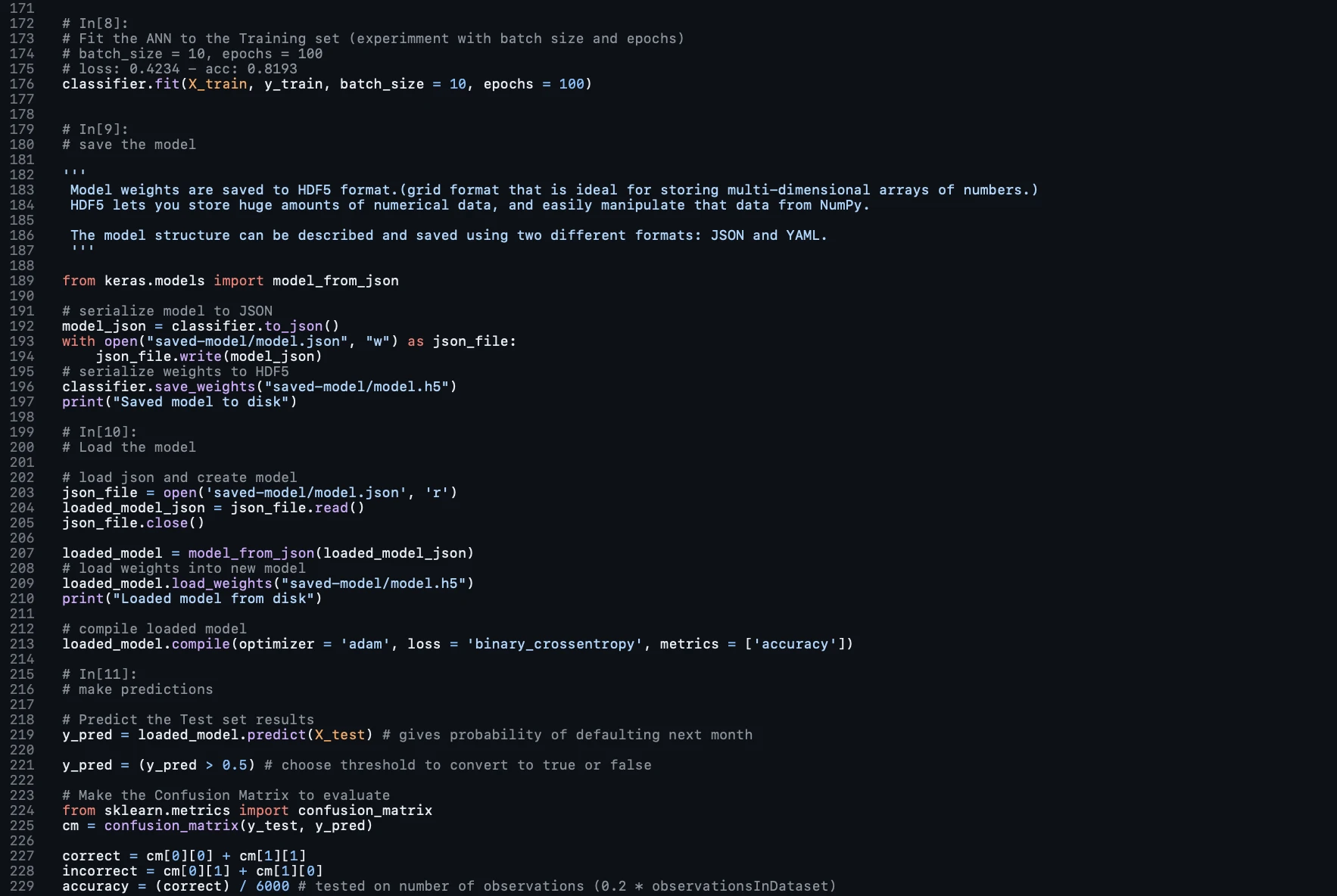
Making Predictions and Evaluating the Model
Finally, we can begin making predictions on the test set using the predict method and evaluating the model's performance. The predictions would be binary outcomes (default or no default), and the evaluation would typically be based on metrics such as accuracy, precision, recall, and the F1 score.
For binary outcomes, a threshold is set (commonly 0.5) to decide which class to assign each prediction. Predictions with a probability above the threshold will be assigned to one class, and those below to the other.
We create a confusion matrix, which is a performance measurement for machine learning classification. The confusion matrix compares the actual outcomes with the predicted outcomes and is a useful tool for understanding the performance of the classification model.
You can view the complete code including the dataset used on GitHub.



